(1)
Multimedia Communication
Research Department
AT&T Bell Laboratories 4F-605
101 Crawfords Corner Road
Holmdel, New Jersey 07733-3030
Seligmann: (908) 949-4290, doree@research.att.com
Edmark: (908) 949-9223, edmark@research.att.com
(2)
School of Engineering and Applied Science
University of Pennsylvania
P.O. Box 1166
Philadelphia, Pennsylvania 19105
(215) 736-8355
mercuri@gradient.cis.upenn.edu
We have addressed this problem through the use of assurances that are designed to provide information about the connectivity, presence, focus, and activity in an environment that is part virtual and part real. We describe how independent network media services (a virtual meeting room service, a holophonic sound service, an application sharing service, and a 3D augmented reality visualization system) were designed to work together, providing users with coordinated cohesive assurances for virtual contexts in multimedia, multiparty communication and interaction.
When two parties establish a communication connection, they create a virtual context in which their communication resides, but which coexists with and depends upon the real physical world. We have implemented a model to represent one such virtual context, the virtual meeting room[1] -- an interactive environment where conferees may organize, display and manage multiple media streams. The virtual meeting room is an electronic place where users meet and interact with each other and with objects and tools, such as video streams or computer programs. This model establishes a framework on which presentation methods for displaying media outputs to each user are based. It also provides a framework for the design of new media services.
In ordinary phone calls we rely on cues that indicate state (the dial tone, busy signal), connectivity (the other person's voice, static on the line) as well as focus (interjecting "uhuh" or hearing a television in the background). These cues, even if they are not explicitly intended for these purposes, provide information that help assure us about the state and nature of our connection as well as the quality of our interaction. As the complexity of multimedia systems and services grows, so does each participant's uncertainty with regard to the current state of those services, their level and type of connectivity, and the activities of the other participants. The cues we are accustomed to using for two-party connections are not necessarily scalable for multiparty, multimedia systems. For example, it would be unreasonable to expect everyone in a multiparty call to utter "uhuh" to indicate that they are listening.
Different media can be exploited to provide assurances for the other media services. Hence, graphics can, in part, convey presence; while audio can, in part, convey activity. It is in this way that we have enhanced our multimedia interactive environment with synthesized media cues. These cues create assurances that provide context for the conference setting, thus better representing the content of the materials presented, and improving interactions among participants. They also indicate the state of the services provided, as well as the level of participation.
Plate 1 shows Rebecca's view of the environment as she browses through it.
PLATE 1: Rebecca's view of the environment.
From this vantage point, she sees the visualization of the physical world below, consisting of some offices at AT&T Bell Laboratories. In the office at the back, John is shown using his computer and phone. In the foreground, Dorie is in her office, likewise using her computer and phone. Here, John and Dorie, and each of their computers and phones, are represented in a ghosted fashion, indicating that they are each telepresent elsewhere. A virtual meeting room hovers above. This room contains John and Dorie and the equipment they have brought with them to share audio and data: their computers and phones. All of the objects in the room are opaque, indicating their telepresence in this virtual place. Connectivity is shown by the cables attaching the devices in the virtual room to their ghosted counterparts in the real world below; data flow is indicated by the animated contents moving through these cables. Rebecca's location and movement in the virtual environment is conveyed through visual and audio cues to the other people in the environment. Rebecca sees the virtual meeting room, who is in it, and what the participants are doing (because this room and that information is explicitly available to her) and, at the same time, John and Dorie can hear Rebecca as she passes by and they can elect to call her to join their meeting.
Plate 2 shows John's view of a virtual meeting room in which he is telepresent, seated at the round table with a document facing him.
PLATE 2: John's view of the Virtual Meeting Room.
To his left is Dorie, to his right is Rebecca. The audio and graphical visualization is constructed from his individual vantage point in this virtual place. The monophonic signals from Dorie's and Rebecca's voices are convolved to correspond to their locations in the virtual meeting room. All three participants are editing a document together. This document is actually a shared X-Window application that is texture-mapped into the 3D environment. Dorie currently has input control, that is, she alone can type into the application, as indicated by the red line connecting her keyboard to the document. Rebecca is currently pointing to a figure in the document, depicted by the cue stick emanating from her direction. Audio cues are generated to indicate activities in the room. Sampled keyboard presses are spatially located near Dorie, while tapping sounds are located near the shared document.
All the information presented originates from the collection of network media services in use: the meeting room service, the shared application program service, the holophonic sound service, and the 3D visualization service. These services together produce the customized integrated multimedia presentation and interfaces to the system for each user.
The above examples illustrate assurances designed to reinforce information about the state, connectivity and focus of objects in the virtual environment. In the remainder of this paper, we emphasize 1) the importance of using a unifying model for virtual context as the basis for multimedia communication and interaction and 2) the types of assurance techniques used within this model. We will also describe how our underlying infrastructure and shared protocols for multimedia services have enabled us to implement a variety of assurances presented by cooperating media services. Users of our system need not have the same equipment or software in order to interact with each other. We will show examples from several different configurations.
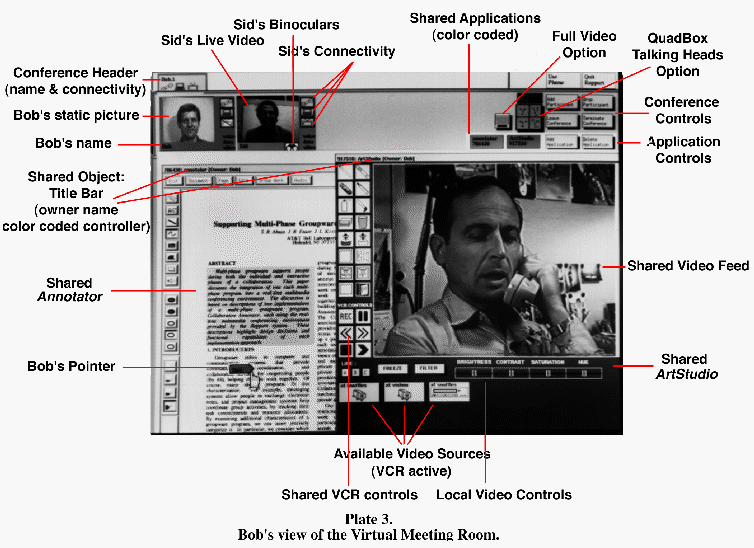
PLATE 3: Bob's view of the Virtual Meeting Room.
The graphical interface dynamically generates coordinated presentations and control mechanisms for shared resources, connectivity, and presence. Controls and state information are presented in sets and every user is presented with his own customized view of the meeting rooms. The graphical interfaces indicate the current level of participation of each user and what other media capabilities are available. The representation of each participant includes his name, a picture or live video, and various indicators of presence and connectivity. The binoculars below Sid's live video feed notify Bob that Sid is viewing Bob's talking head. The application program window frames and corresponding iconic representations indicate who is currently providing input, who can provide input, and where the program is executing. This information is conveyed using the state information transmitted by the individual media services, not by a central controlling module.
A virtual meeting can be as simple as an audio conference call. Here, the ability to identify individual data streams is essential to effective interaction. When a participant starts talking, we need to know who she is and how to recognize her. In a two-party communication, once the initial identification of the talkers are made, no further identity tags are needed for the duration of the call. When a third person is added, the dynamics of the conversation necessarily change. The auditory cues that we use to keep from interrupting one another in a two-person interaction are not sufficient as more parties join the conference. Less- aggressive individuals are often left out, and the other participants may even wonder (or query) if they are still "on the line." If a group is added (say via a speaker-phone), there may be a sense that unidentified listeners are in the room, silently monitoring the discussion, which may be disconcerting to some parties. Various participants may want to put themselves "on hold" in order to carry on private discussions, and then rejoin the group at a later point. It is useful to all parties to know who is still around and just observing quietly, and who is temporarily absent from the session. The virtual meeting room can be used to reveal and clarify this information, augmenting the virtual interaction by providing cues that are associated with face-to-face meetings.
Our multimedia communication system is built on an architecture we call MR (Meeting Room). Briefly, MR is a platform-free, transport- free, device-free, hardware-free infrastructure on which (cooperating) network-based media services are built. The rich representation maintained by each module in the system facilitates the implementation of assurances.
Each media service (i.e. video, audio, etc.) is comprised of a network Server and a local Manager for each individual user. The Server may have associated servers and devices, and the Manager may have local clients (such as an interface), devices and servers. The Server and Managers each maintain representations of the following base classes: virtual meeting rooms (the persistent contexts), conferees (persons associated with the room), materials (objects in the room), and connections.
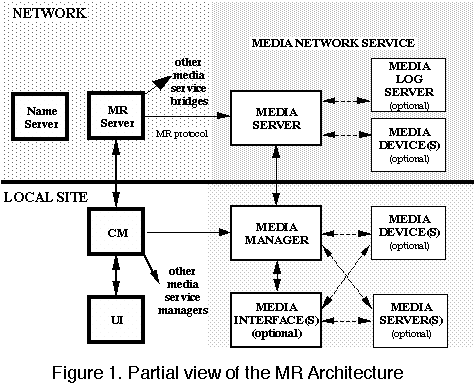
Figure 1 shows a partial view of MR.
FIGURE 1: Partial view of the MR Architecture.
In the network, the MR Server maintains the state of all the virtual meeting rooms and also the states of the associated participants and media services. The MR Server has access to a name server that describes registered objects. On the local site shown, a Conversation Manager (CM) communicates with the MR Server. It has a user- interface (UI) that allows the user to issue meeting room commands (creating, entering, leaving room; associating and disassociating media services; inviting or calling people to join, etc.).
Virtual meeting rooms are persistent, serving as electronic rendezvous places for people to meet, acting as depositories for media objects, and providing structure for reestablishing services. Yet the system is not connection-based, as meeting rooms can exist even when devoid of users and/or objects. The MR Server maintains a representation for each room, in the network, until it is explicitly torn down. Each local site corresponds to one user. A user can move physical locations, change hardware configurations, and still access the people and objects in any given virtual meeting room. Connections are simply dropped when not needed and (re)established to bring media services into a room at any time. A user can access a meeting room from any point as long as there is a local CM that can communicate with the MR Server. Each network service is handled by local Managers that communicate to network Servers. For example, a user can first enter a virtual meeting room from a location via a phone. His phone Manager communicates with the phone Server in order to add him to the conference call. (Note that this location need not be registered in advance; local sites are dynamically established and associated with particular users.) Similarly, a user can create a virtual meeting room from her office and begin to execute a program within it. She then leaves the virtual room (although it continues to exist) and her physical office, and travels to a remote location. Now, with a different piece of hardware, she may reestablish contact with the MR Server and join the virtual room where the still-executing program is located.
We can view the sharing of a medium within the context of a virtual meeting room in two ways: first, as shared objects, and second, as modes of interaction. In an audio service, an example of a shared object is a musical CD that everyone in the virtual meeting room can hear, while one mode of interaction is shared voice. In a video service, an example of a shared object is a video stream that everyone in the virtual meeting room can see, while one mode of interaction is talking heads. Similarly, we define two types of sharing of a windowing system. A shared object could be a program with which everyone in the virtual room can interact, while one mode of interaction is a pointer placed within the context of a program's display.
ASSURANCES Assurance cues are useful for establishing a sense of connectivity and focus in the virtual meeting. Connectivity assurances provide information about the status of the connections between and amongst the participants during the course of communication. They reflect the integrity of the system in operation, and do not simply refer to the physical connections but include the logical ones as well. Focal assurances provide information about the nature of each participant's involvement with the system. They reflect the activities and configurations of each media stream (representing users, objects, devices, etc.) in the system during interaction.[11]
Graphical simulation can be used to provide visual feedback about the virtual meeting and the connectivity among the services, while simultaneously recreating the real world settings in which the users and equipment reside. Texture mapped human models can transcend simple iconified user figures through enhancement with back channel response cues, such as head nods, smiles, arm gestures, and so on, in order to reinforce an active sense of connectivity and presence. For example, if a participant's attention is distracted from the meeting (perhaps by a call to another meeting), the displayed head may momentarily turn away or the eyelids may close.[4]
Holophonic audio (monophonic sound streams to which transforms are applied in order to generate a 3D pair) can be used to simulate a consistent virtual acoustical display where sounds are provided with directional context relative to a listener's vantage point.[5,15,16] Spatial tracking may also be used to correlate each participant's motions in the real world with their position in the virtual environment.[14] Experiments by Alexander Graham Bell[3] in the late 1800's, and in the 1940's at Bell Laboratories by Koenig[10] have long indicated that the spatial localization provided by binaural listening is important for discriminatory processing of audio. Simple stereo pairing allows listeners to subjectively localize sounds in the 3D audio space; reduces the perception of reverberation, background and impulse noises; lends greater ease in differentiation of multiple speech streams; and enhances comprehension of speech in negative signal-to-noise environments. Shimizu[12] observed that, within teleconferencing settings, stereophonics enabled listeners to more easily identify speakers with whom they were unfamiliar.
Although our virtual meeting rooms shall exist in the cold electronic void of cyberspace, they need not be bland and sterile. They should be warm places with character and individuality, where natural conversations are facilitated. When we go to a restaurant, the sights and smells that greet us as we proceed through the door, prepare us for the feast ahead. As we approach a lecture hall, the murmuring of the crowd (or their snoring) indicates to us the level of anticipation of the gathered group. So too, when we enter a virtual meeting room, we should be presented with cues that aid us in understanding behaviors and expectations for the meeting we have joined. These cues can also provide contextual assurances for system state and connectivity levels.
A virtual presence can be applied to provide a further transcendental context to the meeting room environment. Companies establish a corporate image that is consistently conveyed through the appearance of their products, physical plant, logo, and publicity. Individuals create unique atmospheres for themselves in their workspaces and homes. Our virtual settings can similarly use ambient sounds, texture-mapped displays, and carefully designed interfaces in order to establish or enhance a desired mood (i.e. energy can be motivated with bright colors and up-tempo music, calm encouraged by muted background visuals and soft environmental noises). In this way, a sensory experience can be created that contributes positively to the dynamics of the meeting and reinforces the memories taken away by the participants.
Our media services operate within the virtual meeting room model to help support various paradigms, as follows:
Expectation: a sense of anticipation or prior knowledge of activities and surroundings, and the behaviors related to proper and efficient manipulation of the environment. (I know where I am and what to do here.) Sounds within the room may be heard from outside, or as you approach; differently sized and shaped rooms replicate the view and acoustics that would occur in a real room; mood can be augmented with visual and audio ambiance.
Identification: a clear view of who and what is sharing the virtual place is established. (I know who is talking, who is typing, what room we are in.) Each room can have its own image and sound color; people in the room are identifiable by texture-mapped images, location, timbre, volume and diction; audio and visual metaphors for user feedback and control can be applied to spatially placed objects in the environment.[2,9]
Association: relationships between data streams and the individuals who generated or share them are established and may be modified dynamically. (I understand which voice goes with what picture, which program just beeped.) The connection between sounds and users or objects can be reinforced with aural cues, such as the clicking of keys on the keyboard or the whir of a printing device.[13]
Differentiation: similar items must be distinguishable from each other. (I know there is a difference between a participant's voice and the voice in the movie we are watching.) Here too, spatial location, timbre, volume, and virtually applied acoustics and images encourage distinction among objects.
Memory: events have a temporal context. (I remember who was the last person speaking, what was the last thing we did.) Sound and visual imagery will increase retention of the meeting experience and the relationships among the participants. In addition, the persistent character of the virtual meeting room allows for a sense of continuity between sessions, permitting familiar visual and aural elements in the room to trigger memories from previous sessions.[8]
Reference: items exist in the environment within some common context understood by all of the participants. (I am looking at the movie in the back of the room, you are sitting to the left of me and I am on your right.) A global sense of locality ensures that all objects retain their relative positions as the space is observed from different points.
Process: awareness and understanding of one's relationship to the environment, and vice versa, is enhanced. (I know who is listening to me, and can comprehend their reactions to what I do.) Directionality increases the awareness of one's existence within the space, and improves the sense of immediacy of the communication.
Attention: a variety of indicators (verbal, gestural, graphical, etc.) for use in emphasis and articulation should be available across the various media. (I am pointing at you, this text needs to be cut out of that document, that last remark was directed toward me). Volume (whisper, shout) and gesturing can give verbal emphasis; sound metaphors can be used as audio pointers, and color and intensity metaphors can be used as visual pointers.
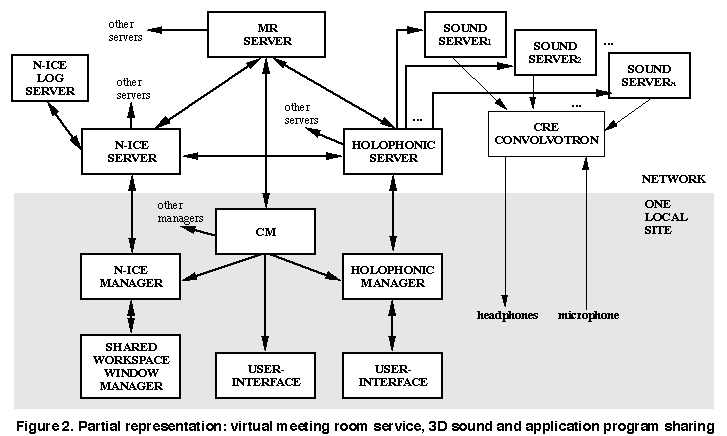
FIGURE 2: Partial representations: virtual meeting room service, 3D sound and application program sharing.
In the network, the MR Server sends MR protocol events to both the N- ICE and holophonic servers. The N-ICE and holophonic servers transmit messages to each other indicating the state of each service. On each local site, each of the related Managers (CM, N-ICE, Holophonic) creates a customized view of the state of the system for the user. Sounds corresponding to the participants and their tools are convolved to reflect their assigned spatial locations from each participant's own perspective.
We have implemented the following categories of audio cues to provide assurances:
3D Realtime Voice. The holophonic Server convolves the monophonic voice signals for each participant. This is not just restricted to the interiors of the virtual meeting rooms. Persons browsing the hallways can also hear the spatially located audio from their vantage points as they wander through the virtual environment.
Generic Events. The MR protocol involves the creation, destruction and use of the virtual meeting rooms. A user is advised of changes in state of the virtual meeting room by messages that are spatially located near the user's ear (such as a whispered briefing). For example, when a user enters a virtual meeting room, she is advised of the people present, and each participant is advised of the new arrival. Sounds for hallway or room events are also assigned to global locations. Broadcast messages, such as audio cues to indicate that a meeting is about to adjourn or commence, are provided.
Interaction with Objects. Audio assurances are used to indicate activity in the room, such as input to shared application programs. N- ICE allows for different input protocols, including chaotic mode, in which anyone in the virtual meeting room can provide input to a particular application program. When simply viewing an application program's windowed displays, a participant may be uncertain (in the absence of additional cues) as to who produced the events that are changing the display. The holophonic service maps selected input events to sampled audio cues and spatially locates them near the representation of the person from whom they originated. For example, we use sampled keyboard clicks for key press events. Using application-specific knowledge, the holophonic service selects different audio cues for similar events. For example, a mouse motion event in a drawing program is presented aurally as a pen scratching noise; the same event in a CAD/CAM program is represented by sampled drafting tool sounds. Inherently collaborative media services, such as a shared whiteboard application, can provide more extensive information about events to aid in mapping to audio cues.
Objects. N-ICE reports the state of each application program as it changes. When a registered application is executed, the holophonic sound service maps successive events to audio cues. For example, when an image viewer opens a window, sampled sounds of a slide projector are played; for document editors, sampled sounds created with paper are used.
Interaction-based events. N-ICE also supports a set of windowed interaction devices, such as pointers and annotators. The holophonic Server uses a tapping sound to accompany pointing.
Participants need not adopt the same set of media services in a virtual meeting room. A participant may choose not to use (or may not be able to use) the N-ICE service. In this case, the holophonic service can provide different aural assurances vis-`-vis N-ICE-specific events (such as the opening of a new application program, someone has just typed a "t", etc.). Furthermore, the MR architecture allows for any media service to provide assurances cues for the same events. Thus, the same event can be presented by combinations of cues, such as visual captions, bridged audio, or synthesized speech, in addition to those described in this paper.
Multimedia systems are for people to use. While we search for better transport algorithms to guarantee data arrival rates and synchronization, new compression techniques and data formats, we must also seek new methods for organizing and humanizing the presentation of this information. Context enhancements within the meeting room model are a step toward providing a seamless transition from the real world to that of the virtual and back again. Architectures, such as MR, make it possible to support persistent, flexible and extensible virtual contexts that facilitate the communication and interaction process.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}